repartition in Spark
repartition 파헤치기
Repartition ?
Spark에서 RDD, Dataset, DataFrame의 작업 최소단위는 partition입니다. 데이터에 Job을 적용할 때 Spark는 최소 단위인 partition으로 쪼개서 task을 수행합니다.하나의 executor가 하나의 task, 즉 하나의 partition에 대해 작업을 수행합니다.
이때, 해당 데이터셋(Dataset, DataFrame) 내부의 partition의 개수, 사이즈, 정렬상태는 task 수행에 영향을 줍니다. 예를 들어 아래와 같은 상황이라면 partition A를 전달받은 executor는 OOM을 피할 수 없을 것입니다.
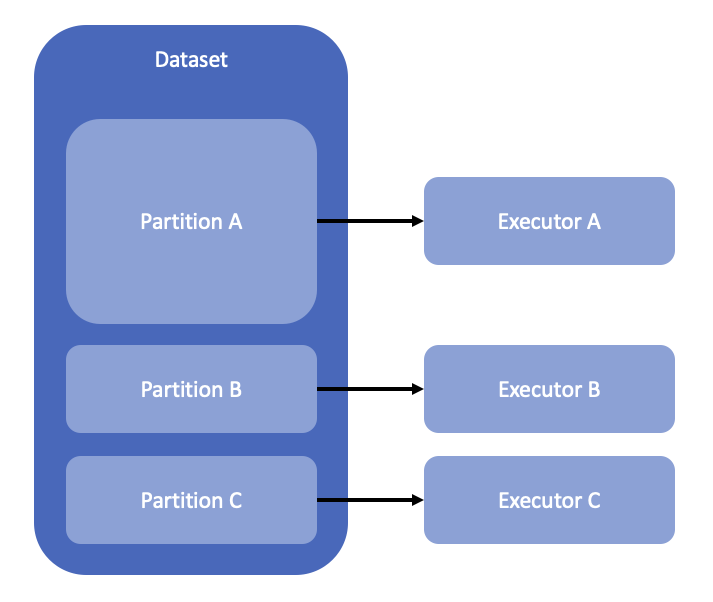
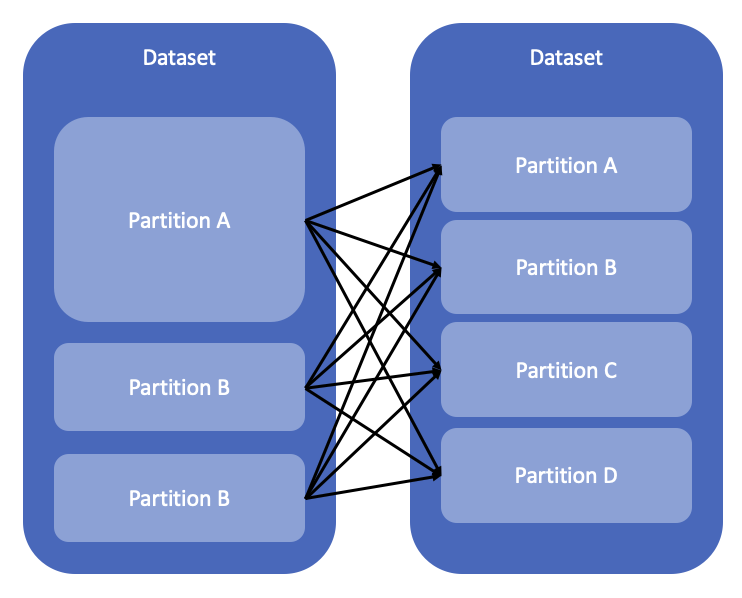
이러한 상황을 피하기 위해, partition들이 동일한 크기를 갖도록 조절(rebalancing)할 수 있는데 이를 repartition이라고 부릅니다. repartition은 필수적으로 shuffle을 동반하는 무거운 작업입니다. 따라서 repartition이 필요한지 심사숙고하여 적절한 수치로 적용해야합니다.
val data_repartitioned = data.repartition(4)
val data_rdd = data_repartitioned.rdd
val partitions = data_rdd.glom.collect()
for (idx <- 0 to 3) {
println("partition"+idx+ " has "+ partitions(idx).size +" rows")
}
partition0 has 1362 rows
partition1 has 1362 rows
partition2 has 1361 rows
partition3 has 1362 rows
repartition 을 적용한 결과 각 partition이 같은 row 수를 갖도록 shuffle하여 각 partition에 재분배했습니다.
Repartition by Specific Column
위에서 보았던 예시처럼 단순히 데이터 사이즈만 분배하는 것이 목적은 아닙니다. partition 전략을 적용할 수 있습니다. 특정 column(Key)을 기준으로 전략을 수립합니다. 전략을 적용한다는 것은 위 예시처럼 partition에 데이터를 무작위로 shuffle하는 것이 아니라 규칙에 따라 partition에 데이터를 shuffle하는 것입니다. 이러한 전략으로 hash partitoin, range partition은 Spark에서 기본으로 제공하고있고, 필요하다면 자신이 직접 전략을 만들어 적용할 수도 있습니다(custom partitioner).
이러한 전략을 적용하게 되면, 이후 partition 기준으로 사용된 column을 사용한 집계/조건 적용 시 쿼리 성능이 향상됩니다.
Hash Partition
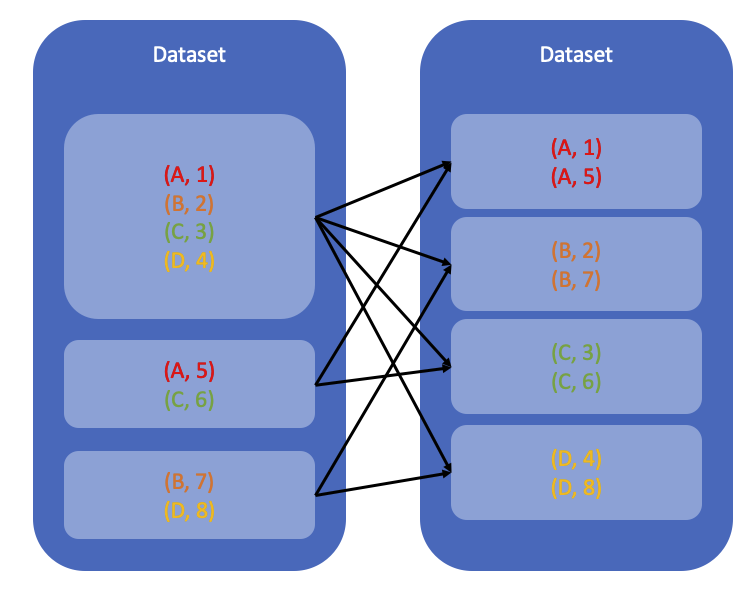
hash partition은 Key에 hash function을 적용하여 계산된 hash value가 같은 값들을 같은 partition에 분배하는 것입니다.
val data_hash_repartitioned = data.repartition(8, $"Day")
val data_rdd = data_hash_repartitioned.rdd
val partitions = data_rdd.glom.collect()
for (idx <- 0 to 7) {
println("partition"+idx+ " has "+ partitions(idx).size +" rows")
println("partition key is " + partitions(idx).map(x => x(2)).toSet)
}
partition0 has 716 rows
partition key is Set(12, 13, 14, 18)
partition1 has 895 rows
partition key is Set(6, 9, 17, 16, 23)
partition2 has 462 rows
partition key is Set(5, 10, 31)
partition3 has 1074 rows
partition key is Set(1, 27, 7, 3, 11, 26)
partition4 has 179 rows
partition key is Set(25)
partition5 has 867 rows
partition key is Set(20, 29, 30, 19, 15)
partition6 has 717 rows
partition key is Set(2, 4, 22, 28)
partition7 has 537 rows
partition key is Set(8, 21, 24)
data 를 8개 partition으로 repartition하였습니다. 각각의 partition에 row가 몇 개나 존재하고, repartition 기준으로 사용한 column인 Day 값을 확인할 수 있습니다. 예를 들어, partition0에는 716 rows가 포함되었고, partition key로 사용된 값은 12, 13, 14, 18입니다. 즉, Day 값이 12, 13, 14, 18인 row는 반드시 partition0 에 속합니다.
Range Partition
range partition은 Key를 지정된 개수만큼의 범위로 나누고, 각각의 범위에 속하는 값을 같은 partition에 분배합니다. pairRDD에 RangePartitioner를 적용하는 방법과 Dataset에서 repartitionByRange를 이용하는 방법이 있습니다.
Partitioner를 이용하기 위해서는 반드시 pairRDD이어야만 합니다.
import scala.collection.SortedSet
def sortSet[A](unsortedSet: Set[A])(implicit ordering: Ordering[A]): SortedSet[A] =
SortedSet.empty[A] ++ unsortedSet
// RDD
val dataRDD = data.rdd.map(x => (x.getInt(3), x.getDouble(4))) // key-value RDD(pair RDD)
val rangePartitioner = new RangePartitioner(5, dataRDD)
val rangedData = dataRDD.partitionBy(rangePartitioner)
val partitions = rangedData.glom.collect()
for (idx <- 0 to 4) {
println("partition"+idx+ " has "+ partitions(idx).size +" rows")
println("partition key is " + sortSet(partitions(idx).map(x => x._1).toSet))
}
// Dataset
val rangedDataset = data.repartitionByRange(5, $"Hour")
val rangedRDD = rangedDataset.rdd
val partitions = rangedRDD.glom.collect()
for (idx <- 0 to 4) {
println("partition"+idx+ " has "+ partitions(idx).size +" rows")
println("partition key is " + sortSet(partitions(idx).map(x => x.getInt(3)).toSet))
}
partition0 has 954 rows
partition key is TreeSet(0, 2, 3)
partition1 has 1460 rows
partition key is TreeSet(5, 6, 8, 9)
partition2 has 730 rows
partition key is TreeSet(11, 12)
partition3 has 1460 rows
partition key is TreeSet(14, 15, 17, 18)
partition4 has 843 rows
partition key is TreeSet(20, 21, 23)
RangePartitioner는 RDD에 적용할 수 있기 때문에 위처럼 DataFrame을 RDD로 변환하여 적용해야합니다. Dataset은 repartitionByRange를 이용하여 적용할 수도 있습니다.Hour column에 해당하는 x.getInt(3) 을 기준으로 Range partition을 적용했습니다. 각 partition은 0~3, 5~9, 11~12, 14~18, 20~23의 5개 구간으로 나뉘어 구간에 해당하는 값들이 partition에 포함되었습니다.
Custom Partitioner
Hash, Range가 아닌 자신이 직접 규칙을 정의하여 reaprtition에 적용시킬 수도 있습니다. 저는 key를 Day 로 두고, 10으로 나눈 나머지를 partition 기준으로 결정하는 CustomPartitioner를 정의하고 적용해보겠습니다. 해당 데이터는 매일 같은 양이 수집된 데이터이므로, Day에 이와 같은 규칙을 적용하면 rebalancing 효과도 나타날 것으로 기대됩니다.
class CustomPartitioner() extends Partitioner {
override def numPartitions: Int = 10
override def getPartition(key: Any): Int = {
val code = key.hashCode() % numPartitions
if (code < 0) {
code + numPartitions
} else {
code
}
}
override def equals(other: scala.Any): Boolean = other match {
case custom: CustomPartitioner => custom.numPartitions == numPartitions
case _ => false
}
}
// https://m.blog.naver.com/syung1104/221103154997
val dataRDD = data.rdd.map(x => (x.getInt(2), x.getDouble(4))) // pairRDD
val customedData = dataRDD.partitionBy(new CustomPartitioner())
val partitions = customedData.glom.collect()
for (idx <- 0 to 9) {
println("partition"+idx+ " has "+ partitions(idx).size +" rows")
println("partition key is " + sortSet(partitions(idx).map(x => x._1).toSet))
}
partition0 has 523 rows
partition key is TreeSet(10, 20, 30)
partition1 has 641 rows
partition key is TreeSet(1, 11, 21, 31)
partition2 has 537 rows
partition key is TreeSet(2, 12, 22)
partition3 has 537 rows
partition key is TreeSet(3, 13, 23)
partition4 has 537 rows
partition key is TreeSet(4, 14, 24)
partition5 has 537 rows
partition key is TreeSet(5, 15, 25)
partition6 has 537 rows
partition key is TreeSet(6, 16, 26)
partition7 has 537 rows
partition key is TreeSet(7, 17, 27)
partition8 has 538 rows
partition key is TreeSet(8, 18, 28)
partition9 has 523 rows
partition key is TreeSet(9, 19, 29)
Day 는 1~ 31까지 존재하고, 이들을 10으로 나눈 나머지(일의 자리)는 0~9까지 존재합니다. 따라서 10개 partition을 생성하였습니다. 위에서 살펴보았던 Hash, Range에 비해 reblancing이 꽤나 잘 되었습니다.
Rebalancing is not guaranteed
위 방법들을 적용했을 때 rebalancing이 항상 보장되는 것은 아닙니다. repartition을 사용하는 경우, 각 partition의 데이터 사이즈가 동일하도록 데이터를 셔플하지만, hash, range, custom repartition은 규칙을 적용할 뿐 rebalancing을 고려하지 않습니다. 위를 비교해보면 hash, range를 적용했을 때는 partiton의 데이터 분포가 불균형합니다. 이에 비해 Day의 특성을 이용하여 repartition을 적용했기에 각 partition의 데이터 분포가 hash, range에 비해 균등합니다.
Sort in Partition
partition 내부를 정렬시킬 수도 있습니다. 예를 들어, 위의 Hash Partition을 적용한 결과 중 하나의 partition 내부를 살펴보겠습니다.
val data_repartitioned = data.repartition(4)
val data_rdd = data_repartitioned.rdd
val partitions = data_rdd.glom.collect()
partitions(0).foreach(x => println(x))
[Year, Month, Day, Hour, Pressure, WetTemp, DryTemp, Humidity, Direction, Speed, City]
[89,1,12,2,944.4,8.2,6.6,5,0,0,Canberra]
[89,1,12,5,945.8,7.9,6.3,4,0,0,Canberra]
[89,1,12,8,948.5,13.2,8.3,2,7,4,Canberra]
[89,1,12,11,948.3,18.1,11.5,5,16,4,Canberra]
[89,1,12,14,947.9,21.4,12.2,2,9,6,Canberra]
...
[89,1,13,2,953.2,14.1,12.4,11,0,0,Canberra]
[89,1,13,5,953.5,13.1,11.1,9,0,0,Canberra]
[89,1,13,8,954.9,15.6,11.8,8,6,5,Canberra]
[89,1,13,11,954.8,18.6,12.7,7,0,0,Canberra]
...
[89,12,18,5,1014.0,16.2,15.3,15,2,18,Gabo Island]
[89,12,18,8,1014.4,18.8,17.4,16,2,22,Gabo Island]
[89,12,18,11,1013.5,20.7,17.9,16,2,24,Gabo Island]
[89,12,18,14,1011.6,20.2,18.0,16,2,24,Gabo Island]
[89,12,18,17,1010.1,20.5,18.1,16,2,24,Gabo Island]
[89,12,18,20,1010.5,18.5,17.2,16,2,20,Gabo Island]
Day가 12, 13, 14, 18인 Row들이 partition 내부에 존재하지만, 정렬되어있지는 않습니다. 이들을 Day, Hour를 기준으로 정렬해놓는다면 추후에 실행되는 작업들에서 실행 시간을 아낄 수 있을 것 같습니다. 이는 sortWithinPartitions를 통해 가능합니다.
val data_repartitioned_sorted = data_repartitioned.sortWithinPartitions($"Day", $"Hour")
val data_rdd = data_repartitioned_sorted.rdd
val partitions = data_rdd.glom.collect()
partitions(0).foreach(x => println(x))
[Year, Month, Day, Hour, Pressure, WetTemp, DryTemp, Humidity, Direction, Speed, City]
[89,4,12,0,945.5,11.1,10.0,9,0,0,Canberra]
[89,5,12,0,952.7,8.2,7.4,6,0,0,Canberra]
[89,6,12,0,948.8,7.4,6.0,4,9,6,Canberra]
[89,7,12,0,944.8,3.8,3.1,2,0,0,Canberra]
[89,8,12,0,957.7,2.0,0.5,-2,8,12,Canberra]
...
[89,1,18,23,942.6,16.0,14.5,13,0,0,Canberra]
[89,3,18,23,955.8,15.8,13.9,13,0,0,Canberra]
[89,11,18,23,945.9,12.3,11.5,11,4,2,Canberra]
[89,12,18,23,947.8,17.8,12.0,6,0,0,Canberra]
Day, Hour를 기준으로 partition 내부가 정렬되어 있음을 확인할 수 있습니다.
repartitionAndSortWithinPartitions(link)는 repartition과 sort를 동시에 적용해줍니다. piarRDD에서만 사용할 수 있습니다.
val dataRDD = data.rdd.map(x => (x.getInt(2), x.getDouble(4)))
val dataRepartitionedSorted = dataRDD.repartitionAndSortWithinPartitions(new HashPartitioner(5))
[참고]